

Be part of our every day and weekly newsletters for the newest updates and unique content material on industry-leading AI protection. Study Extra
Chinese language AI startup DeepSeek, recognized for difficult main AI distributors with open-source applied sciences, simply dropped one other bombshell: a brand new open reasoning LLM referred to as DeepSeek-R1.
Primarily based on the lately launched DeepSeek V3 mixture-of-experts mannequin, DeepSeek-R1 matches the efficiency of o1, OpenAI’s frontier reasoning LLM, throughout math, coding and reasoning duties. One of the best half? It does this at a way more tempting price, proving to be 90-95% extra inexpensive than the latter.
The discharge marks a serious leap ahead within the open-source area. It showcases that open fashions are additional closing the hole with closed business fashions within the race to synthetic normal intelligence (AGI). To indicate the prowess of its work, DeepSeek additionally used R1 to distill six Llama and Qwen fashions, taking their efficiency to new ranges. In a single case, the distilled model of Qwen-1.5B outperformed a lot greater fashions, GPT-4o and Claude 3.5 Sonnet, in choose math benchmarks.
These distilled fashions, together with the main R1, have been open-sourced and can be found on Hugging Face under an MIT license.
What does DeepSeek-R1 convey to the desk?
The main target is sharpening on synthetic normal intelligence (AGI), a degree of AI that may carry out mental duties like people. Numerous groups are doubling down on enhancing fashions’ reasoning capabilities. OpenAI made the primary notable transfer within the area with its o1 mannequin, which makes use of a chain-of-thought reasoning course of to sort out an issue. By RL (reinforcement studying, or reward-driven optimization), o1 learns to hone its chain of thought and refine the methods it makes use of — finally studying to acknowledge and proper its errors, or strive new approaches when the present ones aren’t working.
Now, persevering with the work on this path, DeepSeek has launched DeepSeek-R1, which makes use of a mixture of RL and supervised fine-tuning to deal with complicated reasoning duties and match the efficiency of o1.
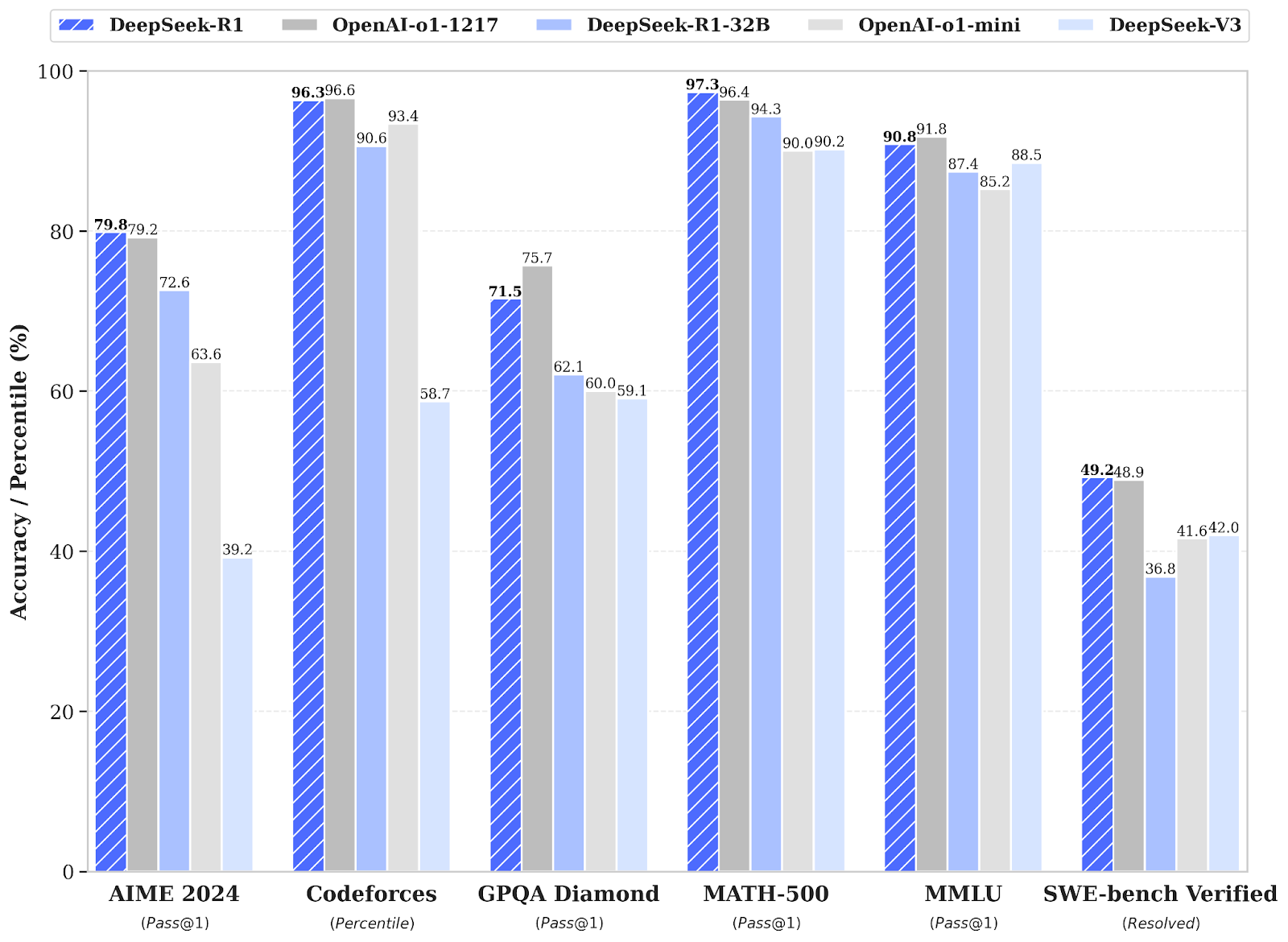
When examined, DeepSeek-R1 scored 79.8% on AIME 2024 arithmetic checks and 97.3% on MATH-500. It additionally achieved a 2,029 ranking on Codeforces — higher than 96.3% of human programmers. In distinction, o1-1217 scored 79.2%, 96.4% and 96.6% respectively on these benchmarks.
It additionally demonstrated robust normal data, with 90.8% accuracy on MMLU, simply behind o1’s 91.8%.
The coaching pipeline
DeepSeek-R1’s reasoning efficiency marks an enormous win for the Chinese language startup within the US-dominated AI house, particularly as the whole work is open-source, together with how the corporate skilled the entire thing.
Nevertheless, the work isn’t as easy because it sounds.
Based on the paper describing the analysis, DeepSeek-R1 was developed as an enhanced model of DeepSeek-R1-Zero — a breakthrough mannequin skilled solely from reinforcement studying.
https://twitter.com/DrJimFan/standing/1881353126210687089
The corporate first used DeepSeek-V3-base as the bottom mannequin, growing its reasoning capabilities with out using supervised information, basically focusing solely on its self-evolution via a pure RL-based trial-and-error course of. Developed intrinsically from the work, this means ensures the mannequin can resolve more and more complicated reasoning duties by leveraging prolonged test-time computation to discover and refine its thought processes in better depth.
“Throughout coaching, DeepSeek-R1-Zero naturally emerged with quite a few highly effective and fascinating reasoning behaviors,” the researchers observe within the paper. “After 1000’s of RL steps, DeepSeek-R1-Zero displays tremendous efficiency on reasoning benchmarks. For example, the move@1 rating on AIME 2024 will increase from 15.6% to 71.0%, and with majority voting, the rating additional improves to 86.7%, matching the efficiency of OpenAI-o1-0912.”
Nevertheless, regardless of exhibiting improved efficiency, together with behaviors like reflection and exploration of alternate options, the preliminary mannequin did present some issues, together with poor readability and language mixing. To repair this, the corporate constructed on the work executed for R1-Zero, utilizing a multi-stage method combining each supervised studying and reinforcement studying, and thus got here up with the improved R1 mannequin.
“Particularly, we start by gathering 1000’s of cold-start information to fine-tune the DeepSeek-V3-Base mannequin,” the researchers defined. “Following this, we carry out reasoning-oriented RL like DeepSeek-R1- Zero. Upon nearing convergence within the RL course of, we create new SFT information via rejection sampling on the RL checkpoint, mixed with supervised information from DeepSeek-V3 in domains similar to writing, factual QA, and self-cognition, after which retrain the DeepSeek-V3-Base mannequin. After fine-tuning with the brand new information, the checkpoint undergoes a further RL course of, taking into consideration prompts from all situations. After these steps, we obtained a checkpoint known as DeepSeek-R1, which achieves efficiency on par with OpenAI-o1-1217.”
Way more inexpensive than o1
Along with enhanced efficiency that just about matches OpenAI’s o1 throughout benchmarks, the brand new DeepSeek-R1 can also be very inexpensive. Particularly, the place OpenAI o1 prices $15 per million enter tokens and $60 per million output tokens, DeepSeek Reasoner, which is predicated on the R1 mannequin, costs $0.55 per million enter and $2.19 per million output tokens.
https://twitter.com/EMostaque/standing/1881310721746804810
The mannequin could be examined as “DeepThink” on the DeepSeek chat platform, which is analogous to ChatGPT. customers can entry the mannequin weights and code repository by way of Hugging Face, below an MIT license, or can go along with the API for direct integration.
Source link


