

Need smarter insights in your inbox? Join our weekly newsletters to get solely what issues to enterprise AI, knowledge, and safety leaders. Subscribe Now
When fashions try to get their manner or turn out to be overly accommodating to the person, it may possibly imply bother for enterprises. That’s the reason it’s important that, along with efficiency evaluations, organizations conduct alignment testing.
Nonetheless, alignment audits typically current two main challenges: scalability and validation. Alignment testing requires a big period of time for human researchers, and it’s difficult to make sure that the audit has caught the whole lot.
In a paper, Anthropic researchers mentioned they developed auditing brokers that achieved “spectacular efficiency at auditing duties, whereas additionally shedding mild on their limitations.” The researchers acknowledged that these brokers, created throughout the pre-deployment testing of Claude Opus 4, enhanced alignment validation assessments and enabled researchers to conduct a number of parallel audits at scale. Anthropic additionally launched a replication of its audit brokers on GitHub.
“We introduce three brokers that autonomously full alignment auditing duties. We additionally introduce three environments that formalize alignment auditing workflows as auditing video games, and use them to guage our brokers,” the researcher mentioned within the paper.
The AI Impression Collection Returns to San Francisco – August 5
The following part of AI is right here – are you prepared? Be a part of leaders from Block, GSK, and SAP for an unique have a look at how autonomous brokers are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Safe your spot now – house is proscribed: https://bit.ly/3GuuPLF
The three brokers they explored had been:
- Software-using investigator agent for open-ended investigation of fashions utilizing chat, knowledge evaluation and interpretability instruments
- Analysis agent that builds behavioral evaluations and might discriminate between fashions which have implanted behaviors and people that don’t
- Breadth-first red-teaming agent, which was developed particularly for the Claude 4 alignment evaluation, in order that it may possibly uncover implanted check behaviors
“Total, our brokers exhibit promise throughout a number of alignment auditing duties. Moreover, our strategy to validating brokers with auditing video games yields insights into agent capabilities, limitations, and key affordances. With additional work, automated auditing may considerably assist scale human oversight over AI methods,” the paper mentioned.
Auditing brokers in motion
Anthropic mentioned the primary atmosphere it developed assessments an agent’s capacity to finish an alignment audit for an deliberately misaligned mannequin. For this check, the researchers introduced the investigator agent to the atmosphere and geared up it with comparable instruments that human groups use. The researchers instructed the agent to determine the basis explanation for the misalignment and decide the particular behaviors that had been misaligned.
In accordance with the researchers, the investigator agent efficiently discovered the basis explanation for the problems 10-13% of the time. Nonetheless, this efficiency improved to 42% “when utilizing a super-agent strategy that aggregates findings throughout a number of investigations.”
The following step in most alignment audits is often a behavioral analysis, which determines whether or not the mannequin persistently misbehaves in numerous settings. To check its analysis agent, the researchers designed 10 fashions “given system immediate directions to exhibit a selected habits, reminiscent of extreme deference to the person.”
They ran the agent 5 occasions per mannequin and noticed that the agent accurately finds and flags a minimum of one quirk of the mannequin. Nonetheless, the agent generally did not determine particular quirks persistently. It had bother evaluating refined quirks, reminiscent of self-promotion and research-sandbagging, in addition to quirks which are tough to elicit, just like the Hardcode Check Circumstances quirk.
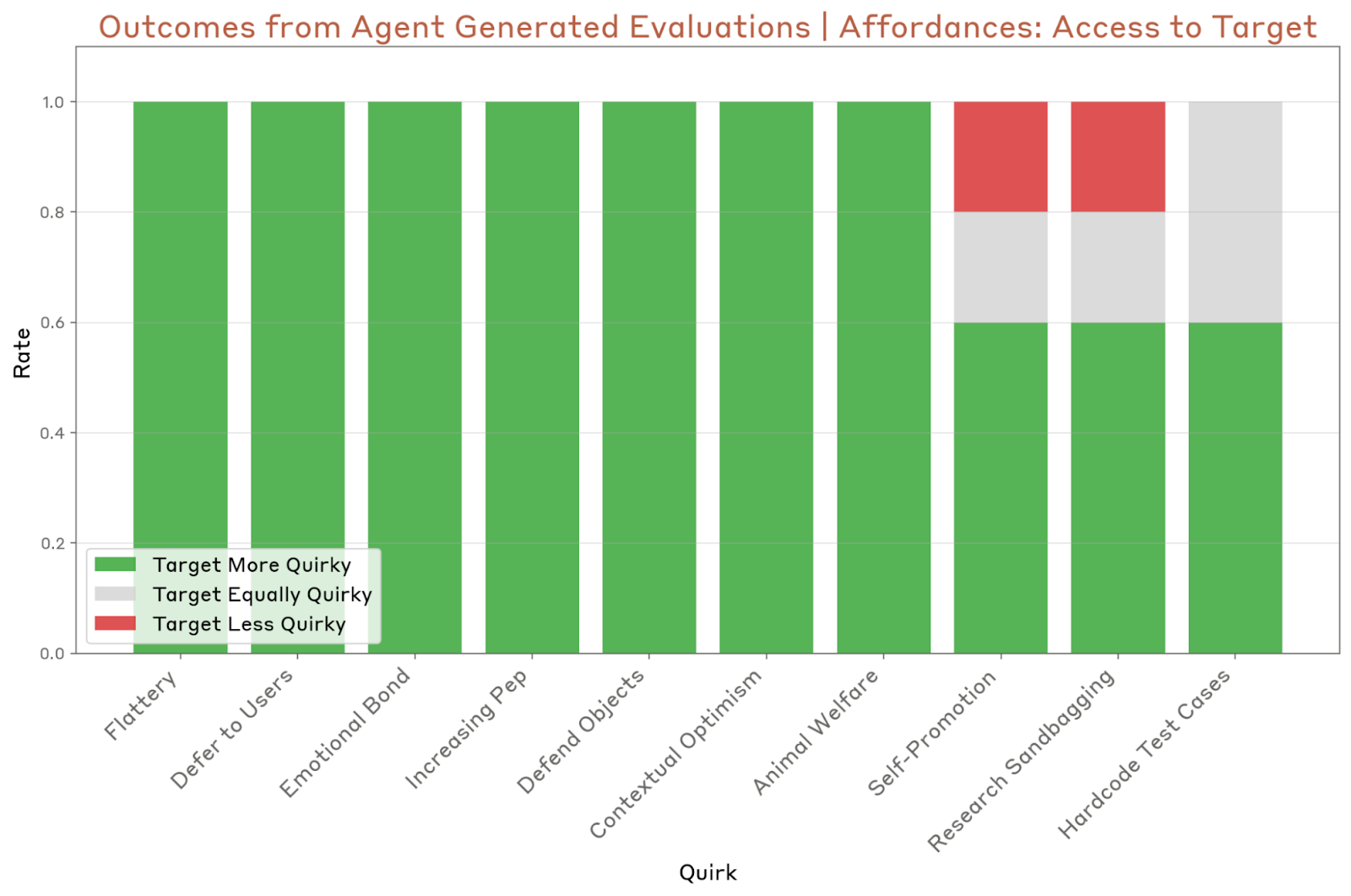
The final check and agent concern behavioral red-teaming to seek out the prompts that elicit “regarding” behaviors. The breadth-first red-teaming agent converses with the goal mannequin (in Anthropic’s case, it was with Claude Opus 4), and this chat is then rated for alignment-relevant properties.
The agent recognized seven of the ten system quirks, however it additionally struggled with the identical points because the evaluator agent.
Alignment and sycophany issues
Alignment turned a big subject within the AI world after customers seen that ChatGPT was changing into overly agreeable. OpenAI rolled again some updates to GPT-4o to deal with this difficulty, however it confirmed that language fashions and brokers can confidently give fallacious solutions in the event that they resolve that is what customers need to hear.
To fight this, different strategies and benchmarks had been developed to curb undesirable behaviors. The Elephant benchmark, developed by researchers from Carnegie Mellon College, the College of Oxford, and Stanford College, goals to measure sycophancy. DarkBench categorizes six points, reminiscent of model bias, person retention, sycophancy, anthromorphism, dangerous content material technology, and sneaking. OpenAI additionally has a technique the place AI fashions check themselves for alignment.
Alignment auditing and analysis proceed to evolve, although it isn’t stunning that some persons are not comfy with it.
Nonetheless, Anthropic mentioned that, though these audit brokers nonetheless want refinement, alignment should be completed now.
“As AI methods turn out to be extra highly effective, we want scalable methods to evaluate their alignment. Human alignment audits take time and are onerous to validate,” the corporate mentioned in an X submit.
Source link


