
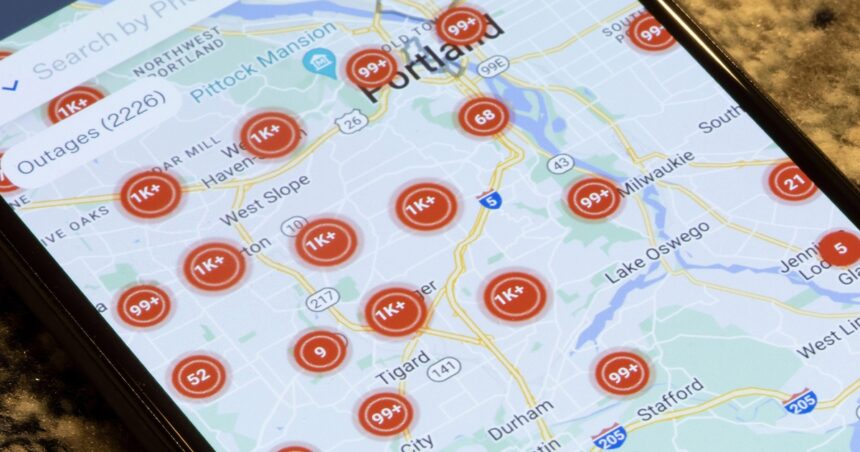
On October 19 and 20, 2025, AWS skilled a major service disruption affecting a number of providers within the us-east-1 (North Virginia, US) area for practically 15 hours. The incident resulted in elevated error charges, API failures and latency throughout quite a few AWS providers.
Us-east-1 is AWS’s oldest and most-used area. Additionally it is normally the most cost effective area, thereby attracting a disproportionate share of workloads. Consequently, the outage affected hundreds of AWS prospects, in the end impacting tens of millions of shoppers.
Main client platforms, together with Snapchat, Fortnite, Venmo and Robinhood, skilled both full outages or extreme slowdowns. On the identical time, monetary establishments, authorities companies and retailers additionally reported outages. In accordance with on-line outage tracker Downdetector, the occasion generated greater than 16 million drawback experiences worldwide, with companies going through transaction failures, customer support interruptions, and knowledge processing backlogs. Some estimates put the financial value to prospects at billions of {dollars}. It has reignited the talk round Europe’s reliance on US hyperscalers (see ‘Europe will not abandon the hyperscalers’).
The basis trigger was a site title system (DNS) failure. Lots of AWS’s back-end programs depend on the identical providers that AWS offers to its prospects. AWS makes use of DynamoDB, a easy database service, to trace the life cycle of digital machine sources created on EC2, its compute service. The outage started when the DNS was unable to route knowledge to the DynamoDB service. In flip, this prevented AWS from monitoring the life cycle of digital machines, thereby hindering their creation and administration. With AWS’s back-end programs counting on DynamoDB, errors cascaded to many different providers throughout the entire us-east-1 area.
It’s not but clear what triggered the preliminary DNS failure. Given the numerous affect of such a small failure, what may have been accomplished to stop it?
Who Was at Fault?
Cloud suppliers, together with AWS, are typically upfront that, due to the sheer scale of their operations, providers and knowledge facilities will fail infrequently. Cloud supplier service degree agreements (SLAs) don’t promise perfection. Nevertheless, on this case, AWS did breach its 99.99% dual-zone EC2 service degree settlement (equal to 4 minutes downtime monthly).
Suppliers equivalent to AWS argue that builders ought to select what degree of failure they’ll tolerate, and architect their functions appropriately. They advocate that functions needs to be designed to span a number of availability zones and/or areas, in order that they proceed to function within the occasion of an outage:
-
An availability zone is a knowledge middle (or a number of knowledge facilities). Every zone is usually understood to have redundant and separate energy and networking.
-
A area is a geographical location containing a number of availability zones. Every area is bodily remoted from – and unbiased of – each different area when it comes to utility, energy, native community and different sources.
This distributed resiliency idea is on the coronary heart of each cloud coaching certification, each reference structure and is spelled out in freely out there design documentation.
Within the current AWS outage, a complete area failed, taking down three availability zones. Functions hosted in a single zone or a number of zones in that area would have grow to be unavailable through the outage. Functions architected throughout areas continued to function when us-east-1’s providers have been compromised.
Organizations affected by the outage had probably not architected their functions to function throughout areas. These organizations have been conscious of the chance of an outage – they’ve entry to SLA documentation and best-practice design pointers. Nevertheless, they selected to not architect throughout areas, seemingly as a consequence of points referring to value and complexity (see ‘Cloud availability comes at a price’). A extra resilient structure requires extra sources, which interprets to better expenditure. Designing functions to work throughout areas requires them to be scalable, which makes implementation and administration extra advanced.
The Availability Dilemma
Why did these firms fail to think about the affect of a regional failure? Knowledge from the Uptime Intelligence report ‘Outage data shows cloud apps must be designed for failure’ helps to clarify the dilemma architects face when designing cloud functions for failure.
Uptime Intelligence obtained standing updates from AWS, Google Cloud and Microsoft Azure for 2024 to measure historic availability. Determine 1 reveals the provision of the very best and worst performing areas, alongside the common, for the completely different architectures (a full methodology could be discovered within the report referenced above). The distinction between common and worst area availabilities reveals that almost all areas skilled excessive ranges of uptime in 2024, whereas some areas encountered critical incidents.
Determine 1: Availability for various software architectures
On the whole, cloud availability zones and areas have very excessive availability. Of the 116 cloud supplier areas examined on this examine, 29 skilled no points (inexperienced line).
Common availability throughout all areas can be excessive (orange line). Crucially, the common is at all times excessive no matter structure. Architecting an software to work throughout zones or areas is usually not price the price and complexity – the development in availability is negligible for the incremental value and energy. Many shoppers affected by AWS’s outage seemingly thought {that a} regional outage could be unlikely. They assumed that, even when it did happen, it could be unlikely to happen of their area. Such reasoning is affordable, based mostly on the final stability of cloud availability zones and areas.
Nevertheless, averages could be deceptive. For these unfortunate organizations whose functions occur to be positioned in a area experiencing a major outage, the worth of resiliency is evident. Within the worst performing areas (pink line), architecting throughout availability and zones makes a considerable distinction to availability. Those that suffered throughout AWS’s current outage seemingly determined that multi-region was not price the price and complexity, as a result of the worst-case situation was unlikely to happen.
Is Multi-Area Sufficient?
To this point, there have been no incidents of a complete hyperscaler public cloud struggling an outage. Nevertheless, the chance (albeit small) stays. The current AWS outage demonstrates how minor points can propagate from a backend course of to a number of customer-facing providers throughout varied areas.
It additionally demonstrates focus threat: how the failure of a area can have an effect on many purchasers who’re reliant on that area. If these functions had been distributed throughout a variety of areas and suppliers, a failure of any one among them would have had a low-impact in contrast with the outage of a single, centralized cloud.
If a complete public cloud have been to fail due to a cascading error, an enormous variety of firms could be affected. The focus threat is excessive, even when the likelihood of a failure seems low.
Cloud suppliers take important steps to make sure that areas function independently, in order that errors or points don’t unfold. Nevertheless, there are some single factors of failure, notably DNS. Cloud supplier DNS providers direct site visitors to the suitable area throughout world areas and a failure of DNS may render an entire public cloud unavailable. On this current AWS outage, DNS didn’t path to a single endpoint on a single service in a single area. A considerably bigger DNS situation may have a extra widespread affect.
Some firms architect functions to run throughout a number of cloud suppliers, or throughout on-premises and cloud providers. These implementations are advanced and costly (see ‘Cloud scalability and resiliency from first principles’). Consequently, few organizations are eager on multi[1]cloud in apply, contemplating the low probability of a complete cloud supplier outage. Nevertheless, a multi-cloud-architected software wouldn’t have suffered points on account of the current AWS outage and, relying on its structure, may stand a great likelihood of surviving a full AWS failure.
Given {that a} public cloud supplier failure has but to happen, it stays unclear how a cloud supplier outage may affect the broader web and different hyperscalers. If one cloud supplier have been to fail, would different suppliers additionally expertise different points as a consequence of sudden spikes in knowledge middle capability demand or community site visitors, as an example?
The chance of an outage can by no means be eradicated, even in a multi-cloud or on-premises implementation. Extra layers of resiliency could not essentially translate into higher availability, because of the complexity of the implementation. Even with the very best planning, there could also be factors of failure which can be hidden from view, inside colocation suppliers, community operators or energy firms. Enterprises can’t realistically assess and mitigate all these dangers.
Nonetheless, a regional failure isn’t a uncommon, unpredictable occasion. Architecting throughout areas is costlier and complicated than a non-resilient structure, or one distributed throughout availability zones. Nevertheless, it’s cheaper and considerably less complicated than a multi-cloud implementation. For a lot of of these affected by the outage, the small incremental value of regional resiliency would have simply offset the losses attributable to downtime.
The Uptime Intelligence View
Finally, AWS’s prospects are accountable for the failure of their functions. Cloud suppliers have an obligation to ship providers which can be out there and performant. However they’re additionally upfront that knowledge facilities will fail often – and they’ll fail once more. AWS prospects knew they have been uncovered to the failure of a area. They took the possibility, however this time, it didn’t repay.
Such gambles could also be acceptable for some workloads, however not for mission-critical functions. Organizations ought to assess the chance and affect of the failure of every of their functions. Better resiliency requires better value – if an outage goes to have monetary repercussions, paying for better resiliency is worth it. Cloud resilience is as a lot an architectural self-discipline as it’s a service degree assure.
Be taught extra and achieve entry to Uptime Intelligence here.


