
Serverless Capabilities Are Nice for Small Duties
Cloud-based computing utilizing serverless features has gained widespread reputation. Their enchantment for implementing new performance derives from the simplicity of serverless computing. You should use a serverless operate to analyse an incoming picture or course of an occasion from an IoT machine. It’s quick, easy, and scalable. You don’t should allocate and keep computing sources – you simply deploy utility code. The foremost cloud distributors, together with AWS, Microsoft, and Google, all supply serverless features.
For easy or advert hoc functions, serverless features make a variety of sense. However are they acceptable for advanced workflows that learn and replace endured, mission-critical information units? Take into account an airline that manages 1000’s of flights every single day. Scalable, NO-SQL information shops (like Amazon Dynamo DB or Azure Cosmos DB) can retailer information describing flights, passengers, luggage, gate assignments, pilot scheduling, and extra. Whereas serverless features can entry these information shops to course of occasions, resembling flight cancellations and passenger rebookings, are they one of the best ways to implement the excessive volumes of occasion processing that airways depend on?
Points and Limitations
The very power of serverless features, specifically that they’re serverless, creates a built-in limitation. By their nature, they require overhead to allocate computing sources when invoked. Additionally, they’re stateless and should retrieve information from exterior information shops. This additional slows them down. They can’t benefit from native, in-memory caching to keep away from information movement; information should all the time movement over the cloud’s community to the place a serverless operate runs.
When constructing massive methods, serverless features additionally don’t supply a transparent software program structure for implementing advanced workflows. Builders have to implement a clear ‘separation of issues’ within the code that every operate runs. When creating a number of serverless features, it’s simple to fall into the entice of duplicating performance and evolving a posh, unmanageable code base. Additionally, serverless features can generate uncommon exceptions, resembling timeouts and quota limits, which have to be dealt with by utility logic.
An Various: Transfer the Code to the Information
We will keep away from the constraints of serverless features by doing the alternative: transferring the code to the information. Think about using scalable in-memory computing to run the code carried out by serverless features. In-memory computing shops objects in main reminiscence distributed throughout a cluster of servers. It might invoke features on these objects by receiving messages. It can also retrieve information and persist adjustments to information shops, resembling NO-SQL shops.
As a substitute of defining a serverless operate that operates on remotely saved information, we are able to simply ship a message to an object held in an in-memory computing platform to carry out the operate. This strategy hastens processing by avoiding the necessity to repeatedly entry a knowledge retailer, which reduces the quantity of information that has to movement over the community. As a result of in-memory information computing is very scalable, it may deal with very massive workloads involving huge numbers of objects. Additionally, extremely accessible message-processing avoids the necessity for utility code to deal with atmosphere exceptions.
In-memory computing presents key advantages for structuring code that defines advanced workflows by combining the strengths of data-structure shops, like Redis, and actor models. Not like a serverless operate, an in-memory information grid can limit processing on objects to strategies outlined by their information sorts. This helps builders keep away from deploying duplicate code in a number of serverless features. It additionally avoids the necessity to implement object locking, which may be problematic for persistent information shops.
Benchmarking Instance
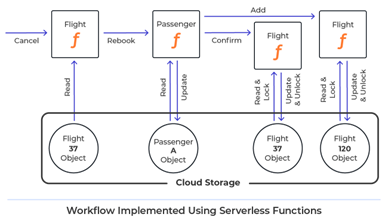
To measure the efficiency variations between serverless features and in-memory computing, we in contrast a easy workflow carried out with AWS Lambda features to the identical workflow constructed utilizing ScaleOut Digital Twins, a scalable, in-memory computing structure. This workflow represented the occasion processing that an airline may use to cancel a flight and rebook all passengers on different flights. It used two information sorts, flight and passenger objects, and saved all cases in Dynamo DB. An occasion controller triggered cancellation for a gaggle of flights and measured the time required to finish all rebookings.
Within the serverless implementation, the occasion controller triggered a lambda operate to cancel every flight. Every ‘passenger lambda’ rebooked a passenger by deciding on a unique flight and updating the passenger’s info. It then triggered serverless features that confirmed removing from the unique flight and added the passenger to the brand new flight. These features required the usage of locking to synchronise entry to Dynamo DB objects.
The digital twin implementation dynamically created in-memory objects for all flights and passengers when these objects have been accessed from Dynamo DB. Flight objects obtained cancellation messages from the occasion controller and despatched messages to passenger digital twin objects. The passenger digital twins rebooked themselves by deciding on a unique flight and sending messages to each the outdated and new flights. Utility code didn’t want to make use of locking, and the in-memory platform routinely endured updates again to Dynamo DB.

Efficiency measurements confirmed that the digital twins processed 25 flight cancellations with 100 passengers per flight greater than 11X sooner than serverless features. We couldn’t scale serverless features to run the goal workload of canceling 250 flights with 250 passengers every, however ScaleOut Digital Twins had no problem processing double this goal workload with 500 flights.

Summing Up
Whereas serverless features are extremely appropriate for small and advert hoc functions, they is probably not your best option when constructing advanced workflows that should handle many information objects and scale to deal with massive workloads. Transferring the code to the information with in-memory computing could also be a more sensible choice. It boosts efficiency by minimising information movement, and it delivers excessive scalability. It additionally simplifies utility design by benefiting from structured entry to information.
To be taught extra about ScaleOut Digital Twins and check this strategy to managing information objects in advanced workflows, go to: https://www.scaleoutdigitaltwins.com/touchdown/scaleout-data-twins.


