
Be part of our each day and weekly newsletters for the newest updates and unique content material on industry-leading AI protection. Be taught Extra
Your complete AI panorama shifted again in January 2025 after a then little-known Chinese language AI startup DeepSeek (a subsidiary of the Hong Kong-based quantitative evaluation agency Excessive-Flyer Capital Administration) launched its highly effective open supply language reasoning mannequin DeepSeek R1 publicly to the world, besting U.S. giants comparable to Meta.
As DeepSeek utilization unfold quickly amongst researchers and enterprises, Meta was reportedly sent into panic mode upon studying that this new R1 mannequin had been skilled for a fraction of the price of many different main fashions but outclassed them for as little as a number of million {dollars} — what it pays a few of its personal AI workforce leaders.
Meta’s entire generative AI technique had till that time been predicated on releasing best-in-class open supply fashions underneath its model title “Llama” for researchers and firms to construct upon freely (a minimum of, if they’d fewer than 700 million month-to-month customers, at which level they’re speculated to contact Meta for particular paid licensing phrases).
But DeepSeek R1’s astonishingly good efficiency on a much smaller funds had allegedly shaken the corporate management and compelled some form of reckoning, with the final model of Llama, 3.3, having been launched only a month prior in December 2024 but already trying outdated.
Now we all know the fruits of that reckoning: immediately, Meta founder and CEO Mark Zuckerberg took to his Instagram account to introduced a new Llama 4 series of models, with two of them — the 400-billion parameter Llama 4 Maverick and 109-billion parameter Llama 4 Scout — out there immediately for builders to obtain and start utilizing or fine-tuning now on llama.com and AI code sharing group Hugging Face.
An enormous 2-trillion parameter Llama 4 Behemoth can also be being previewed immediately, though Meta’s blog post on the releases stated it was nonetheless being skilled, and gave no indication of when it is likely to be launched. (Recall parameters confer with the settings that govern the mannequin’s conduct and that typically extra imply a extra highly effective and sophisticated throughout mannequin.)
One headline characteristic of those fashions is that they’re all multimodal — skilled on, and due to this fact, able to receiving and producing textual content, video, and imagery (hough audio was not talked about).
One other is that they’ve extremely lengthy context home windows — 1 million tokens for Llama 4 Maverick and 10 million for Llama 4 Scout — which is equal to about 1,500 and 15,000 pages of textual content, respectively, all of which the mannequin can deal with in a single enter/output interplay. Meaning a person might theoretically add or paste as much as 7,500 pages-worth-of textual content and obtain that a lot in return from Llama 4 Scout, which might be useful for information-dense fields comparable to drugs, science, engineering, arithmetic, literature and so forth.
Right here’s what else we’ve discovered about this launch to this point:
All-in on mixture-of-experts
All three fashions use the “mixture-of-experts (MoE)” structure method popularized in earlier model releases from OpenAI and Mistral, which basically combines a number of smaller fashions specialised (“consultants”) in several duties, topics and media codecs right into a unified entire, bigger mannequin. Every Llama 4 launch is claimed to be due to this fact a combination of 128 totally different consultants, and extra environment friendly to run as a result of solely the skilled wanted for a selected process, plus a “shared” skilled, handles every token, as an alternative of all the mannequin having to run for each.
Because the Llama 4 weblog put up notes:
Consequently, whereas all parameters are saved in reminiscence, solely a subset of the full parameters are activated whereas serving these fashions. This improves inference effectivity by reducing mannequin serving prices and latency—Llama 4 Maverick might be run on a single [Nvidia] H100 DGX host for simple deployment, or with distributed inference for max effectivity.
Each Scout and Maverick can be found to the general public for self-hosting, whereas no hosted API or pricing tiers have been introduced for official Meta infrastructure. As a substitute, Meta focuses on distribution by means of open obtain and integration with Meta AI in WhatsApp, Messenger, Instagram, and net.
Meta estimates the inference value for Llama 4 Maverick at $0.19 to $0.49 per 1 million tokens (utilizing a 3:1 mix of enter and output). This makes it considerably cheaper than proprietary fashions like GPT-4o, which is estimated to value $4.38 per million tokens, primarily based on group benchmarks.
All three Llama 4 fashions—particularly Maverick and Behemoth—are explicitly designed for reasoning, coding, and step-by-step drawback fixing — although they don’t seem to exhibit the chains-of-thought of devoted reasoning fashions such because the OpenAI “o” sequence, nor DeepSeek R1.
As a substitute, they appear designed to compete extra straight with “classical,” non-reasoning LLMs and multimodal fashions comparable to OpenAI’s GPT-4o and DeepSeek’s V3 — excluding Llama 4 Behemoth, which does seem to threaten DeepSeek R1 (extra on this beneath!)
As well as, for Llama 4, Meta constructed customized post-training pipelines centered on enhancing reasoning, comparable to:
- Eradicating over 50% of “straightforward” prompts throughout supervised fine-tuning.
- Adopting a steady reinforcement studying loop with progressively tougher prompts.
- Utilizing move@okay analysis and curriculum sampling to strengthen efficiency in math, logic, and coding.
- Implementing MetaP, a brand new approach that lets engineers tune hyperparameters (like per-layer studying charges) on fashions and apply them to different mannequin sizes and kinds of tokens whereas preserving the meant mannequin conduct.
MetaP is of explicit curiosity because it may very well be used going ahead to set hyperparameters on on mannequin after which get many different kinds of fashions out of it, rising coaching effectivity.
As my VentureBeat colleague and LLM skilled Ben Dickson opined ont the brand new MetaP approach: “This could save plenty of money and time. It implies that they run experiments on the smaller fashions as an alternative of doing them on the large-scale ones.”
That is particularly crucial when coaching fashions as massive as Behemoth, which makes use of 32K GPUs and FP8 precision, reaching 390 TFLOPs/GPU over greater than 30 trillion tokens—greater than double the Llama 3 coaching information.
In different phrases: the researchers can inform the mannequin broadly how they need it to behave, and apply this to bigger and smaller model of the mannequin, and throughout totally different types of media.
A strong – however not but the most highly effective — mannequin household
In his announcement video on Instagram (a Meta subsidiary, naturally), Meta CEO Mark Zuckerberg stated that the corporate’s “aim is to construct the world’s main AI, open supply it, and make it universally accessible so that everybody on this planet advantages…I’ve stated for some time that I believe open supply AI goes to change into the main fashions, and with Llama 4, that’s beginning to occur.”
It’s a clearly rigorously worded assertion, as is Meta’s weblog put up calling Llama 4 Scout, “the perfect multimodal mannequin on this planet in its class and is extra highly effective than all earlier era Llama fashions,” (emphasis added by me).
In different phrases, these are very highly effective fashions, close to the highest of the heap in comparison with others of their parameter-size class, however not essentially setting new efficiency information. Nonetheless, Meta was eager to trumpet the fashions its new Llama 4 household beats, amongst them:
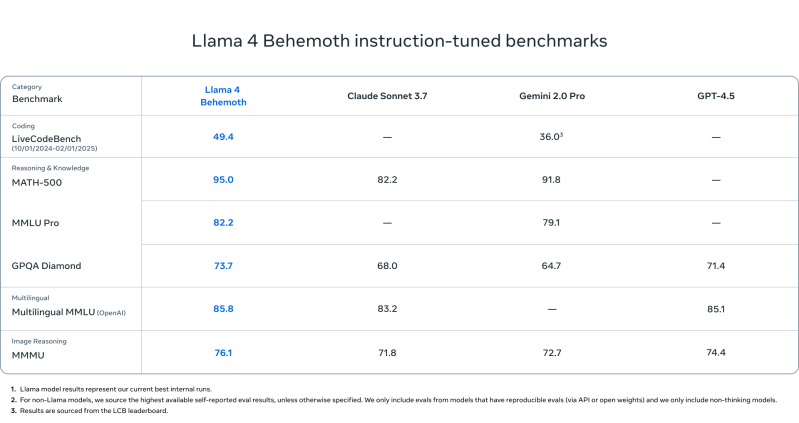
Llama 4 Behemoth
- Outperforms GPT-4.5, Gemini 2.0 Professional, and Claude Sonnet 3.7 on:
- MATH-500 (95.0)
- GPQA Diamond (73.7)
- MMLU Professional (82.2)

Llama 4 Maverick
- Beats GPT-4o and Gemini 2.0 Flash on most multimodal reasoning benchmarks:
- ChartQA, DocVQA, MathVista, MMMU
- Aggressive with DeepSeek v3.1 (45.8B params) whereas utilizing lower than half the energetic parameters (17B)
- Benchmark scores:
- ChartQA: 90.0 (vs. GPT-4o’s 85.7)
- DocVQA: 94.4 (vs. 92.8)
- MMLU Professional: 80.5
- Price-effective: $0.19–$0.49 per 1M tokens

Llama 4 Scout
- Matches or outperforms fashions like Mistral 3.1, Gemini 2.0 Flash-Lite, and Gemma 3 on:
- DocVQA: 94.4
- MMLU Professional: 74.3
- MathVista: 70.7
- Unmatched 10M token context size—preferrred for lengthy paperwork, codebases, or multi-turn evaluation
- Designed for environment friendly deployment on a single H100 GPU

However in any case that, how does Llama 4 stack as much as DeepSeek?
However in fact, there are an entire different class of reasoning-heavy fashions comparable to DeepSeek R1, OpenAI’s “o” sequence (like GPT-4o), Gemini 2.0, and Claude Sonnet.
Utilizing the highest-parameter mannequin benchmarked—Llama 4 Behemoth—and evaluating it to the intial DeepSeek R1 launch chart for R1-32B and OpenAI o1 fashions, right here’s how Llama 4 Behemoth stacks up:
| Benchmark | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
What can we conclude?
- MATH-500: Llama 4 Behemoth is barely behind DeepSeek R1 and OpenAI o1.
- GPQA Diamond: Behemoth is forward of DeepSeek R1, however behind OpenAI o1.
- MMLU: Behemoth trails each, however nonetheless outperforms Gemini 2.0 Professional and GPT-4.5.
Takeaway: Whereas DeepSeek R1 and OpenAI o1 edge out Behemoth on a pair metrics, Llama 4 Behemoth stays extremely aggressive and performs at or close to the highest of the reasoning leaderboard in its class.
Security and fewer political ‘bias’
Meta additionally emphasised mannequin alignment and security by introducing instruments like Llama Guard, Immediate Guard, and CyberSecEval to assist builders detect unsafe enter/output or adversarial prompts, and implementing Generative Offensive Agent Testing (GOAT) for automated red-teaming.
The corporate additionally claims Llama 4 reveals substantial enchancment on “political bias” and says “particularly, [leading LLMs] traditionally have leaned left in relation to debated political and social matters,” that that Llama 4 does higher at courting the best wing…consistent with Zuckerberg’s embrace of Republican U.S. president Donald J. Trump and his get together following the 2024 election.
The place Llama 4 stands to this point
Meta’s Llama 4 fashions convey collectively effectivity, openness, and high-end efficiency throughout multimodal and reasoning duties.
With Scout and Maverick now publicly out there and Behemoth previewed as a state-of-the-art trainer mannequin, the Llama ecosystem is positioned to supply a aggressive open various to top-tier proprietary fashions from OpenAI, Anthropic, DeepSeek, and Google.
Whether or not you’re constructing enterprise-scale assistants, AI analysis pipelines, or long-context analytical instruments, Llama 4 presents versatile, high-performance choices with a transparent orientation towards reasoning-first design.
Source link


