
Be a part of our each day and weekly newsletters for the most recent updates and unique content material on industry-leading AI protection. Be taught Extra
Two in style approaches for customizing giant language fashions (LLMs) for downstream duties are fine-tuning and in-context studying (ICL). In a recent study, researchers at Google DeepMind and Stanford College explored the generalization capabilities of those two strategies. They discover that ICL has larger generalization skill (although it comes at a better computation price throughout inference). Additionally they suggest a novel strategy to get the very best of each worlds.
The findings may help builders make essential choices when constructing LLM purposes for his or her bespoke enterprise information.
Testing how language fashions study new methods
Fine-tuning entails taking a pre-trained LLM and additional coaching it on a smaller, specialised dataset. This adjusts the mannequin’s inner parameters to show it new data or abilities. In-context studying (ICL), then again, doesn’t change the mannequin’s underlying parameters. As a substitute, it guides the LLM by offering examples of the specified process instantly inside the enter immediate. The mannequin then makes use of these examples to determine methods to deal with a brand new, comparable question.
The researchers got down to rigorously evaluate how properly fashions generalize to new duties utilizing these two strategies. They constructed “managed artificial datasets of factual data” with advanced, self-consistent constructions, like imaginary household bushes or hierarchies of fictional ideas.
To make sure they had been testing the mannequin’s skill to study new data, they changed all nouns, adjectives, and verbs with nonsense phrases, avoiding any overlap with the information the LLMs might need encountered throughout pre-training.
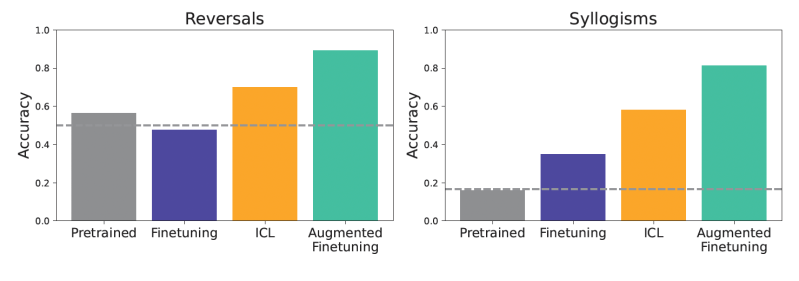
The fashions had been then examined on numerous generalization challenges. As an example, one check concerned easy reversals. If a mannequin was skilled that “femp are extra harmful than glon,” may it accurately infer that “glon are much less harmful than femp”? One other check centered on easy syllogisms, a type of logical deduction. If instructed “All glon are yomp” and “All troff are glon,” may the mannequin deduce that “All troff are yomp”? Additionally they used a extra advanced “semantic construction benchmark” with a richer hierarchy of those made-up information to check extra nuanced understanding.
“Our outcomes are centered totally on settings about how fashions generalize to deductions and reversals from fine-tuning on novel data constructions, with clear implications for conditions when fine-tuning is used to adapt a mannequin to company-specific and proprietary data,” Andrew Lampinen, Analysis Scientist at Google DeepMind and lead creator of the paper, instructed VentureBeat.
To guage efficiency, the researchers fine-tuned Gemini 1.5 Flash on these datasets. For ICL, they fed all the coaching dataset (or giant subsets) as context to an instruction-tuned mannequin earlier than posing the check questions.
The outcomes persistently confirmed that, in data-matched settings, ICL led to raised generalization than customary fine-tuning. Fashions utilizing ICL had been typically higher at duties like reversing relationships or making logical deductions from the supplied context. Pre-trained fashions, with out fine-tuning or ICL, carried out poorly, indicating the novelty of the check information.
“One of many foremost trade-offs to think about is that, while ICL doesn’t require fine-tuning (which saves the coaching prices), it’s typically extra computationally costly with every use, because it requires offering extra context to the mannequin,” Lampinen stated. “However, ICL tends to generalize higher for the datasets and fashions that we evaluated.”
A hybrid strategy: Augmenting fine-tuning
Constructing on the statement that ICL excels at versatile generalization, the researchers proposed a brand new methodology to boost fine-tuning: including in-context inferences to fine-tuning information. The core thought is to make use of the LLM’s personal ICL capabilities to generate extra various and richly inferred examples, after which add these augmented examples to the dataset used for fine-tuning.
They explored two foremost information augmentation methods:
- A native technique: This strategy focuses on particular person items of knowledge. The LLM is prompted to rephrase single sentences from the coaching information or draw direct inferences from them, reminiscent of producing reversals.
- A world technique: The LLM is given the total coaching dataset as context, then prompted to generate inferences by linking a selected doc or reality with the remainder of the supplied data, resulting in an extended reasoning hint of related inferences.
When the fashions had been fine-tuned on these augmented datasets, the positive aspects had been vital. This augmented fine-tuning considerably improved generalization, outperforming not solely customary fine-tuning but in addition plain ICL.

“For instance, if one of many firm paperwork says ‘XYZ is an inner instrument for analyzing information,’ our outcomes counsel that ICL and augmented finetuning might be simpler at enabling the mannequin to reply associated questions like ‘What inner instruments for information evaluation exist?’” Lampinen stated.
This strategy provides a compelling path ahead for enterprises. By investing in creating these ICL-augmented datasets, builders can construct fine-tuned fashions that exhibit stronger generalization capabilities.
This could result in extra sturdy and dependable LLM purposes that carry out higher on various, real-world inputs with out incurring the continual inference-time prices related to giant in-context prompts.
“Augmented fine-tuning will typically make the mannequin fine-tuning course of costlier, as a result of it requires a further step of ICL to enhance the information, adopted by fine-tuning,” Lampinen stated. “Whether or not that extra price is merited by the improved generalization will depend upon the precise use case. Nonetheless, it’s computationally cheaper than making use of ICL each time the mannequin is used, when amortized over many makes use of of the mannequin.”
Whereas Lampinen famous that additional analysis is required to see how the parts they studied work together in several settings, he added that their findings point out that builders might wish to contemplate exploring augmented fine-tuning in circumstances the place they see insufficient efficiency from fine-tuning alone.
“In the end, we hope this work will contribute to the science of understanding studying and generalization in basis fashions, and the practicalities of adapting them to downstream duties,” Lampinen stated.
Source link


