
Need smarter insights in your inbox? Join our weekly newsletters to get solely what issues to enterprise AI, knowledge, and safety leaders. Subscribe Now
Deep Cogito, a lesser-known AI analysis startup based mostly in San Francisco based by ex-Googlers, has launched 4 new open-ish large language models (LLMs) that try one thing few others do: Studying the way to motive extra successfully over time — and get higher at it on their very own.
The fashions, launched as a part of Cogito’s v2 household, vary from 70 billion to 671 billion parameters and can be found for AI builders and enterprises to make use of beneath a mixture of restricted and absolutely open licensing phrases. They embody:
- Cogito v2-70B (Dense)
- Cogito v2-109B (Combination-of-experts)
- Cogito v2-405B (Dense)
- Cogito v2-671B (MoE)
Dense and MoE fashions are every suited to totally different wants. Dense 70B and 405B variant fashions activate all parameters on each ahead go, making them extra predictable and simpler to deploy throughout a variety of {hardware}.
They’re very best for low-latency functions, fine-tuning and environments with restricted GPU capability. MoE fashions, such because the 109B and 671B variations, use a sparse routing mechanism to activate only some specialised “knowledgeable” subnetworks at a time, permitting for a lot bigger whole mannequin sizes with out proportional will increase in compute price.
The AI Impression Collection Returns to San Francisco – August 5
The subsequent section of AI is right here – are you prepared? Be part of leaders from Block, GSK, and SAP for an unique take a look at how autonomous brokers are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Safe your spot now – area is restricted: https://bit.ly/3GuuPLF
This makes them well-suited for high-performance inference duties, analysis into advanced reasoning or serving frontier-level accuracy at decrease runtime expense. In Cogito v2, the 671B MoE mannequin serves because the flagship, leveraging its scale and routing effectivity to match or exceed main open fashions on benchmarks — whereas utilizing considerably shorter reasoning chains.
The fashions can be found now on Hugging Face for obtain and utilization by enterprises and on Unsloth for local usage, or, for many who can’t host the mannequin inferences on their very own {hardware}, by utility programming interfaces (APIs) from Together AI, Baseten and RunPod.
There’s additionally a quantized “8-bit floating point (FP8)” model of the 671B mannequin, which reduces the scale of the numbers used to characterize the mannequin’s parameters from 16-bits to 8-bits, serving to customers run large fashions sooner, cheaper and on extra accessible {hardware} — typically with solely a negligible hit to efficiency (95 to 99%). Nevertheless, this could barely degrade mannequin accuracy, particularly for duties requiring fine-grained precision (some math or reasoning issues).
All 4 Cogito v2 fashions are designed as hybrid reasoning programs: They’ll reply instantly to a question, or, when wanted, mirror internally earlier than answering.
Crucially, that reflection isn’t just runtime habits — it’s baked into the coaching course of itself.
These fashions are skilled to internalize their very own reasoning. Meaning the very paths they take to reach at solutions — the psychological steps, so to talk — are distilled again into the fashions’ weights.
Over time, they be taught which traces of pondering truly matter and which don’t.
As Deep Cogito’s weblog put up notes, the researchers “disincentivize the mannequin from ‘meandering extra’ to have the ability to arrive on the reply, and as a substitute develop a stronger instinct for the appropriate search trajectory for the reasoning course of.”
The outcome, Deep Cogito claims, is quicker, extra environment friendly reasoning and a common enchancment in efficiency, even in so-called “customary” mode.
Self-improving AI
Whereas many within the AI neighborhood are simply encountering the corporate, Deep Cogito has been quietly constructing for over a 12 months.
It emerged from stealth in April 2025 with a sequence of open-source fashions skilled on Meta’s Llama 3.2. These early releases confirmed promising outcomes.
As VentureBeat beforehand reported, the smallest Cogito v1 fashions (3B and 8B) outperformed Llama 3 counterparts throughout a number of benchmarks — typically by extensive margins.
Deep Cogito CEO and co-founder Drishan Arora — beforehand a lead LLM engineer at Google — described the corporate’s long-term aim as constructing fashions that may motive and enhance with every iteration, very similar to how AlphaGo refined its technique by self-play.
Deep Cogito’s core methodology, iterated distillation and amplification (IDA), replaces hand-written prompts or static academics with the mannequin’s personal evolving insights.
What’s ‘machine instinct’?
With Cogito v2, the staff took that loop to a a lot bigger scale. The central concept is easy: Reasoning shouldn’t simply be an inference-time software; it needs to be a part of the mannequin’s core intelligence.
So, the corporate applied a system the place the mannequin runs reasoning chains throughout coaching, after which is skilled on its intermediate ideas.
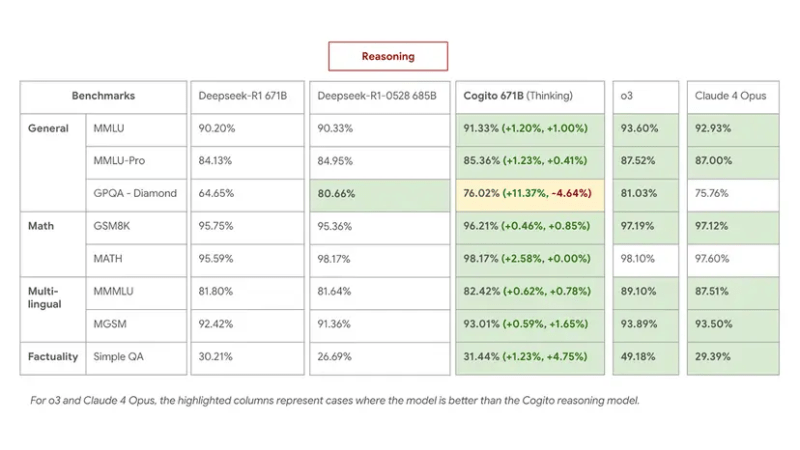
This course of yields concrete enhancements, in accordance with inner benchmarks. The flagship 671B MoE mannequin outperforms DeepSeek R1 in reasoning duties, matching or beating its newest 0528 mannequin whereas utilizing 60% shorter reasoning chains.

On MMLU, GSM8K and MGSM, Cogito 671B MoE’s efficiency was roughly on par with high open fashions like Qwen1.5-72B and DeepSeek v3, and approached the efficiency tier of closed fashions like Claude 4 Opus and o3.
Particularly:
- Cogito 671B MoE (reasoning mode) matched DeepSeek R1 0528 throughout multilingual QA and common data duties, and outperformed it on technique and logical deduction.
- In non-reasoning mode, it exceeded DeepSeek v3 0324, suggesting that the distilled instinct carried actual efficiency weight even with out an prolonged reasoning path.
- The mannequin’s potential to finish reasoning in fewer steps additionally had downstream results: Decrease inference prices and sooner response occasions on advanced prompts.
Arora explains this as a distinction between looking for a path versus already realizing roughly the place the vacation spot lies.
“For the reason that Cogito fashions develop a greater instinct of the trajectory to take whereas looking at inference time, they’ve 60% shorter reasoning chains than Deepseek R1,” he wrote in a thread on X.
What sorts of duties do Deep Cogito’s new fashions excel at when utilizing their machine instinct?
A few of the most compelling examples from Cogito v2’s inner testing spotlight precisely how this manifests in use.
In a single math-heavy immediate, a consumer asks whether or not a practice touring at 80 mph can attain a metropolis 240 miles away in beneath 2.5 hours.
Whereas many fashions simulate the calculation step-by-step and sometimes make unit conversion errors, Cogito 671B displays internally, determines that 240 ÷ 80 = 3 hours, and accurately concludes that the practice can not arrive in time. It does so with solely a brief inner reasoning hint — beneath 100 tokens — in comparison with the 200-plus utilized by DeepSeek R1 to succeed in the identical reply.
In one other instance involving authorized reasoning, a consumer asks whether or not a selected U.S. Supreme Courtroom ruling would apply to a hypothetical case involving search and seizure. Cogito’s reasoning mode highlights a two-step logic: Dirst figuring out whether or not the hypothetical matches the precedent, then explaining why it does or doesn’t. The mannequin reaches a nuanced reply with clear justification — a form of interpretive reasoning that many LLMs nonetheless wrestle with.
Different duties present enhancements in dealing with ambiguity. On a basic multi-hop query — “If Alice is Bob’s mom, and Bob is Charlie’s father, what’s Alice to Charlie?” — fashions usually get tangled in pronouns. Cogito v2’s fashions accurately determine Alice as Charlie’s grandmother, even in barely reworded variants the place different open fashions falter.
Effectivity at scale
Regardless of the large measurement of the brand new fashions, Deep Cogito claims to have skilled all eight of its Cogito fashions — together with smaller v1 checkpoints — for beneath $3.5 million in whole, in comparison with the reported $100 million plus for a few of OpenAI’s main fashions.
That features knowledge technology, artificial reinforcement, infrastructure and greater than 1,000 coaching experiments. In comparison with the nine-figure budgets of different frontier fashions, it’s a fraction of the everyday spend.
Arora attributes this frugality to the corporate’s core thesis: Smarter fashions want higher priors, no more tokens.
By instructing the mannequin to skip redundant or deceptive reasoning paths, Cogito v2 delivers stronger efficiency with out ballooning inference time.
That’s a significant tradeoff for customers operating fashions on API infrastructure or edge gadgets the place latency and price matter.
What’s subsequent for Deep Cogito and v2?
The discharge of Cogito v2 just isn’t a closing product, however an iterative step. Arora describes the corporate’s roadmap as “hill climbing” — operating fashions, studying from their reasoning traces, distilling them and repeating the loop. Over time, every mannequin turns into a stepping stone for the subsequent.
Each mannequin Deep Cogito has launched is open supply, and the corporate says that can stay true for future iterations.
Already, its work has attracted consideration and assist from backers like Benchmark’s Eric Vishria and South Park Commons’ Aditya Agarwal.
Infrastructure companions embody Hugging Face, Collectively AI, RunPod, Baseten, Meta’s Llama staff and Unsloth.
For builders, researchers, and enterprise groups, the fashions can be found now. Builders can run them regionally, evaluate modes or fine-tune for particular use circumstances.
And, for the broader open-source AI neighborhood, Cogito v2 presents greater than only a new benchmark winner — it proposes a unique solution to construct intelligence. Not by pondering tougher, however by studying the way to assume higher.
Source link


