
Tuochao Chen, a College of Washington doctoral scholar, lately toured a museum in Mexico. Chen would not communicate Spanish, so he ran a translation app on his cellphone and pointed the microphone on the tour information. However even in a museum’s relative quiet, the encircling noise was an excessive amount of. The ensuing textual content was ineffective.
Numerous applied sciences have emerged recently promising fluent translation, however none of those solved Chen’s drawback of public areas. Meta’s new glasses, for example, perform solely with an remoted speaker; they play an automated voice translation after the speaker finishes.
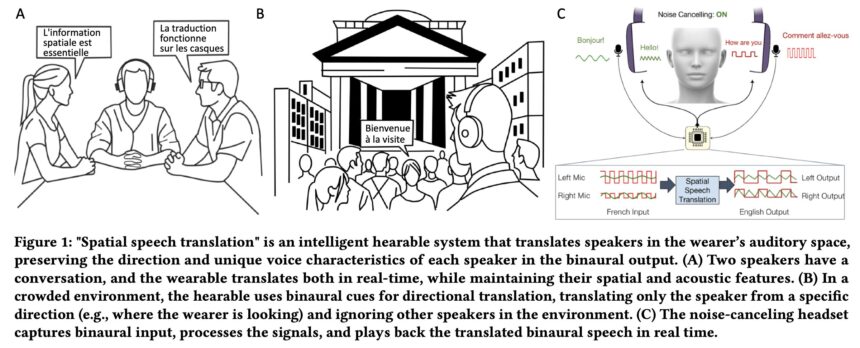
Now, Chen and a group of UW researchers have designed a headphone system that translates several speakers without delay, whereas preserving the route and qualities of individuals’s voices. The group constructed the system, known as Spatial Speech Translation, with off-the-shelf noise-canceling headphones fitted with microphones. The group’s algorithms separate out the totally different audio system in an area and observe them as they transfer, translate their speech and play it again with a 2-4 second delay.
The team presented its research Apr. 30 on the ACM CHI Convention on Human Elements in Computing Methods in Yokohama, Japan. The code for the proof-of-concept machine is offered for others to construct on. “Different translation tech is constructed on the belief that just one individual is talking,” stated senior creator Shyam Gollakota, a UW professor within the Paul G. Allen College of Pc Science & Engineering. “However in the true world, you may’t have only one robotic voice speaking for a number of folks in a room. For the primary time, we have preserved the sound of every individual’s voice and the route it is coming from.”
The system makes three improvements. First, when turned on, it instantly detects what number of audio system are in an indoor or out of doors area.
“Our algorithms work just a little like radar,” stated lead creator Chen, a UW doctoral scholar within the Allen College. “In order that they’re scanning the area in 360 levels and consistently figuring out and updating whether or not there’s one individual or six or seven.”
The system then interprets the speech and maintains the expressive qualities and quantity of every speaker’s voice whereas working on a tool, such cell units with an Apple M2 chip like laptops and Apple Imaginative and prescient Professional. (The group averted utilizing cloud computing due to the privateness considerations with voice cloning.) Lastly, when audio system transfer their heads, the system continues to trace the route and qualities of their voices as they alter.
The system functioned when examined in 10 indoor and out of doors settings. And in a 29-participant take a look at, the customers most popular the system over fashions that did not monitor audio system by area.
In a separate person take a look at, most individuals most popular a delay of 3-4 seconds, because the system made extra errors when translating with a delay of 1-2 seconds. The group is working to cut back the pace of translation in future iterations. The system at the moment solely works on commonplace speech, not specialised language comparable to technical jargon. For this paper, the group labored with Spanish, German and French—however earlier work on translation fashions has proven they are often skilled to translate round 100 languages.
“This can be a step towards breaking down the language limitations between cultures,” Chen stated. “So if I am strolling down the road in Mexico, despite the fact that I do not communicate Spanish, I can translate all of the folks’s voices and know who stated what.”
Qirui Wang, a analysis intern at HydroX AI and a UW undergraduate within the Allen College whereas finishing this analysis, and Runlin He, a UW doctoral scholar within the Allen College, are additionally co-authors on this paper.
Extra data:
Tuochao Chen et al, Spatial Speech Translation: Translating Throughout House With Binaural Hearables, Proceedings of the 2025 CHI Convention on Human Elements in Computing Methods (2025). DOI: 10.1145/3706598.3713745
Quotation:
AI-powered headphones supply group translation with voice cloning and 3D spatial audio (2025, Might 10)
retrieved 10 Might 2025
from https://techxplore.com/information/2025-05-ai-powered-headphones-group-voice.html
This doc is topic to copyright. Aside from any truthful dealing for the aim of personal examine or analysis, no
half could also be reproduced with out the written permission. The content material is supplied for data functions solely.


